
The ability to gather and analyze information from the web is an invaluable skill. Web scraping, the process of extracting data from websites, is a powerful tool that can provide insights into various domains, from market research to competitive analysis. In this post, I’ll walk you through a I’ll walk through a Python example that scrapes book titles from Toscrape, a website designed for practicing web scraping.
The Tools: Python’s Beautiful Soup and Requests
For this project, I utilized three of Python’s most popular libraries for web scraping: BeautifulSoup ,requests, and json . While there are many tools available, these libraries offer a balance of simplicity and power, making them ideal for both beginners and seasoned developers.
Before you are able to use these tools you must have them installed. If you do not have them installed, simply use pip. Json does not have to be installed as it is a built-in module in Python. In your Python environment run the following:
pip install requests beautifulsoup4Writing the Scraper Code:
Step One: Import the essential libraries.
requestsfor sending HTTP requests to Indeed’s website.BeautifulSoupfrom thebs4package for parsing HTML and extracting the data we need.- json for collecting the extracted data.
import requests
import json
from bs4 import BeautifulSoupStep Two: Make the HTTPS Request.
We then specify the URL of the webpage we want to scrape and make an HTTP GET request to fetch its content.
url = "https://books.toscrape.com/"
response = requests.get(url)Step Three: Parsing the HTML Content
We use BeautifulSoup to parse the HTML content returned by the server..
soup = BeautifulSoup(response.content, 'html.parser')Step Four: Parse the HTML Content.
We use BeautfulSoup to parse the HTML content that is returned by the GET request. The “html.parser” argument specifies the parser library we want to use.
soup = BeautifulSoup(response.text, 'html.parser')Step Five: Extracting Book Titles.
We find all the <h3> tags, which contain the book titles, and store them in a list.
titles = soup.find_all('h3')
book_titles = [title.text for title in titles]Step Six: Saving to JSON.
Finally, we save the list of book titles to a JSON file.
with open('book_titles.json', 'w') as f:
json.dump(book_titles, f, indent=4)Full Code:
Here’s the what the complete Python script for scraping book titles from Toscrape and saving them to a JSON file should look like.
import requests
import json
from bs4 import BeautifulSoup
# Making the HTTP request
url = "http://books.toscrape.com/"
response = requests.get(url)
# Parsing the HTML content
soup = BeautifulSoup(response.content, 'html.parser')
# Extracting book titles
titles = soup.find_all('h3')
book_titles = [title.text for title in titles]
# Saving to JSON
with open('book_titles.json', 'w') as f:
json.dump(book_titles, f, indent=4)
Key Insights:
After you run your script open the json file in the code editor. For this project I used VS Code(Visual Studio Code).
You should have some data that looks like the following:
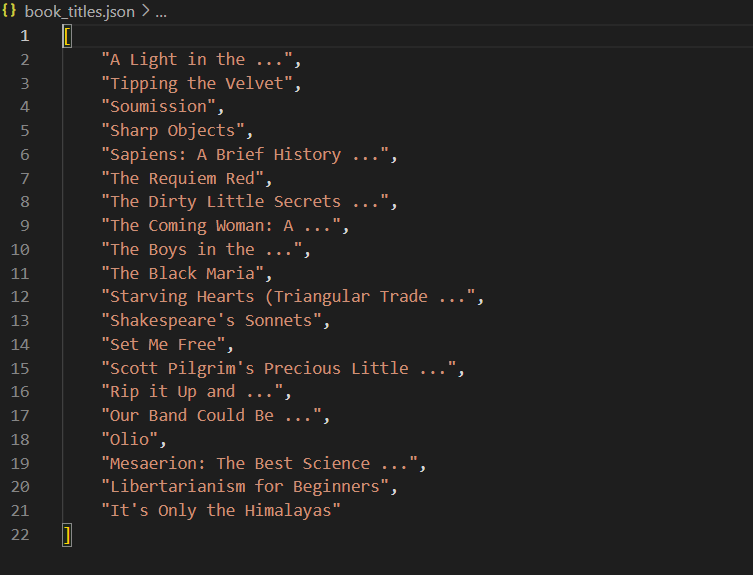
Conclusion:
And there you have it. A successful web scraper! Web scraping is a powerful tool for data extraction and analysis. This hands-on guide should give you a good start in your web scraping journey. Always remember to check a website’s terms of service before scraping.